Our instructors from Datascope Analytics designed the bootcamp around a number of projects.
In week 2 & 3, we were all let loose on movie revenue data scraped from Box Office Mojo. The major goal was to predict a movie-related value of choice by using a linear regression model, optionally involving logarithmic and/or polynomial terms.
The first days were spent on writing and running the web scraper. I used Beautiful Soup and good old regular expressions to parse and convert the messy Box Office Mojo data into a nice and clean comma-separated file.
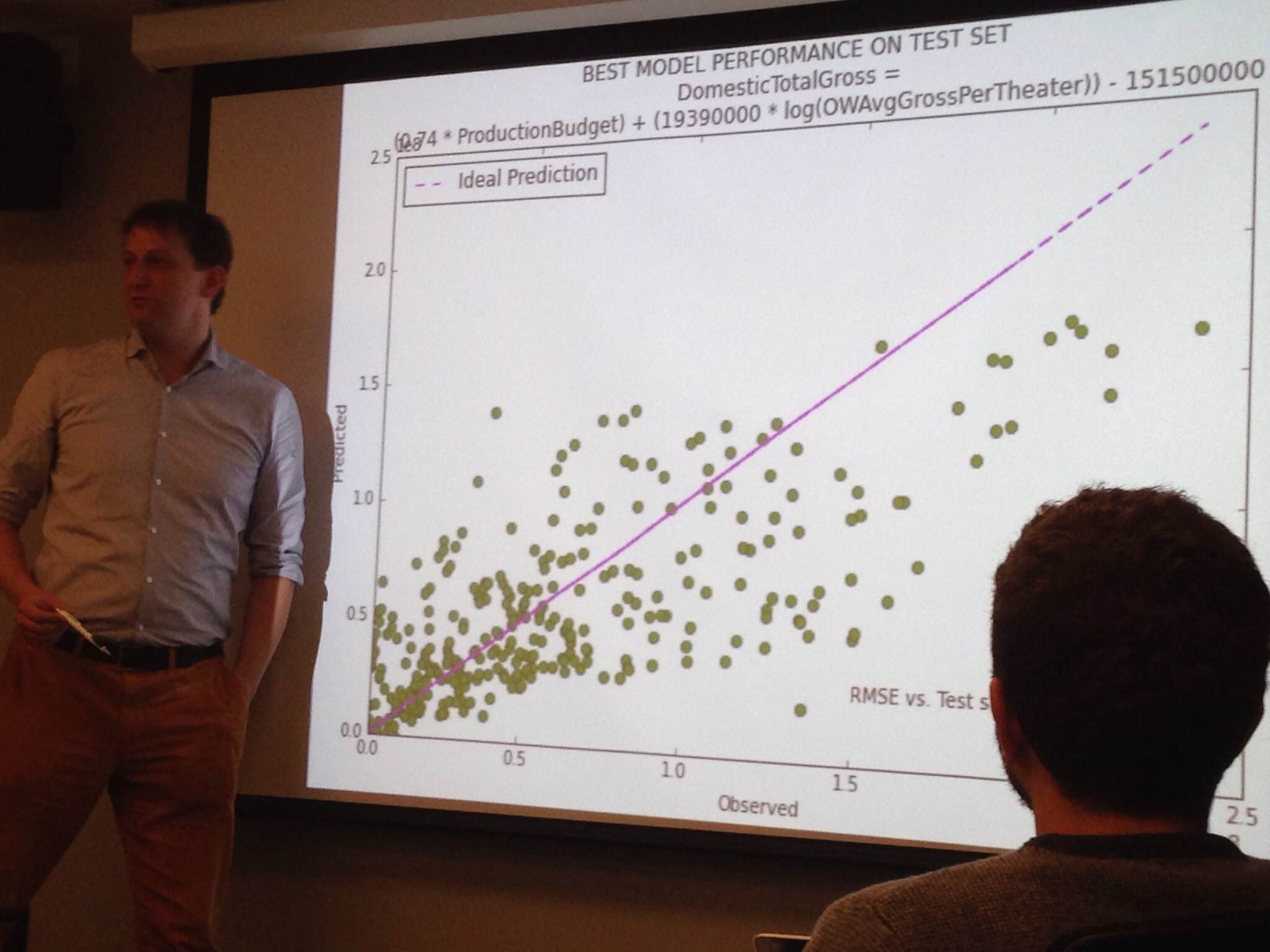
The scope of my personal project shrunk as the data came in and the days went by. In the end, after many iterations in IPython, I got to fit a number of multilinear regression models with statsmodels, using sklearn for model evaluation (root-mean-squared error), and the inevitable pyplot for visualization.
On Friday, the whole class delivered their presentations. My first-ever Keynote presentation was for a ficticious investor known by the name of Dino Brangelino. My conclusion: knowing the box office revenue of the opening weekend -on top of the production budget- reduces total revenue prediction error by 15%.

A not-so-random sample of subjects from my fellow students’ talks:
-
how to convince laggards among the actors and actresses to go on Twitter, by predicting how many followers they would have if they did
-
can monthly consumer optimism predict the mutual prevalence of movie genres?
-
does the choice of a distributor help to secure an Oscar nomination?
-
which actor, actress, director or producer is overpaid or underpaid, given the gross revenue of the movies they have contributed to?
-
does the co-featuring network of actors/actresses determine movie revenue?